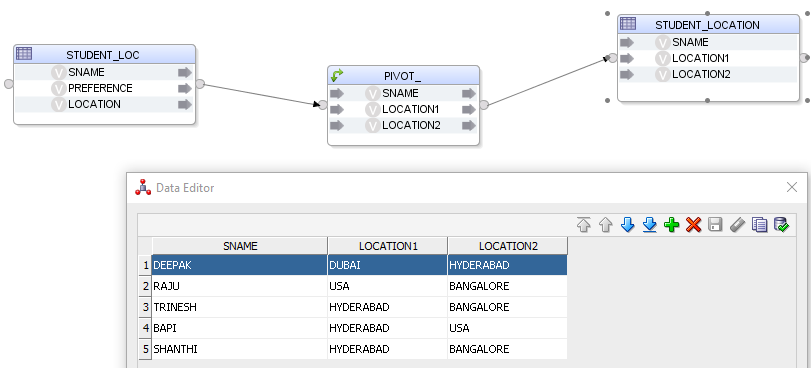
How to Implement PIVOT component in ODI 12c?
Scenario:
To avoid redundant data
Scripts:
CREATE TABLE STUDENT_LOC(
SNAME VARCHAR2(30),
PREFERENCE VARCHAR2(20),
LOCATION VARCHAR2(20));
INSERT INTO STUDENT_LOC VALUES('TRINESH','LOCATION1','HYDERABAD');
INSERT INTO STUDENT_LOC VALUES('TRINESH','LOCATION2','BANGALORE');
INSERT INTO STUDENT_LOC VALUES('SHANTHI','LOCATION1','HYDERABAD');
INSERT INTO STUDENT_LOC VALUES('SHANTHI','LOCATION2','BANGALORE');
INSERT INTO STUDENT_LOC VALUES('BAPI','LOCATION1','HYDERABAD');
INSERT INTO STUDENT_LOC VALUES('BAPI','LOCATION2','USA');
INSERT INTO STUDENT_LOC VALUES('RAJU','LOCATION1','USA');
INSERT INTO STUDENT_LOC VALUES('RAJU','LOCATION2','BANGALORE');
INSERT INTO STUDENT_LOC VALUES('DEEPAK','LOCATION1','DUBAI');
INSERT INTO STUDENT_LOC VALUES('DEEPAK','LOCATION2','HYDERABAD');
COMMIT;
CREATE TABLE STUDENT_LOCATION (
SNAME VARCHAR2(30),
LOCATION1 VARCHAR2(20),
LOCATION2 VARCHAR2(20));
/
Steps to Implement:
1. Create new Mapping
2. Drag and drop source
datastore(STUDENT_LOC) and target datastore from model(STUDENT_LOCATION )
3. Drag and drop Pivot
component from component palette into mapping editor
4. Connect output
connector of PIVOT to input connector of Target datastore
It will pop up as below:

Enable checkbox “Create Attributes On Source” and “Auto Map” and click
on OK.
5. Connect output connector
of source datastore to input connector of Pivot Component
6. Disable checkbox “Create
Attributes on Target”
7. Select Pivot
component and go to property inspector
8. For Sname under expression
select “Sname” from source datastore
Row Locator: Select “Preference” Column
from source Datastore
Click ok “+” symbol to create ROW Locator
values
“LOCATION1”
“LOCATION2”
Under “Matching row” for LOCATION1
column in pivot component select “LOCATION1” and for expression select “Location”
Column
Under “Matching row” for LOCATION2
column in pivot component select “LOCATION2” and for expression select “Location”
Column
It looks as below:

9. Select appropriate
knowledge module in physical tab by selecting target datastore (IKM Oracle
insert.Global by default it will comes, you can leave as it)
10. Execute Mapping
Output & Flow: