Scenario 1:
If the lookup value is not available (no match row) then I need to populate default value without any expression.
For example:
Stage fact table is having "department_id" where as in Dimension table is not have that specific "department_id". In that case we need to populate 0 for "deparment_wid".
Scenario 2:
For one lookup code we are having multiple lookup values but we have to pick only one value without using distinct , aggregate and analytical functions
For example:
If lookup table is versioned table (i.e., one lookup code will have multiple values one is current and rest are old values)
Scenario 1:
Employee table is having department_id : 10
Whereas department table is not having deparment_id : 10






In the lookup component, we can see match row rules
Multiple Match rows: (scenario 2) Select first single row (i.e., eff_dt desc - row_wid: 11)
Return a row with the following default values: (scenario 1) row_wid:0 (i.e., whenever there is no match then it will populate with 0)
Please comment out if you have any questions!!!!!!!!
If the lookup value is not available (no match row) then I need to populate default value without any expression.
For example:
Stage fact table is having "department_id" where as in Dimension table is not have that specific "department_id". In that case we need to populate 0 for "deparment_wid".
Scenario 2:
For one lookup code we are having multiple lookup values but we have to pick only one value without using distinct , aggregate and analytical functions
For example:
If lookup table is versioned table (i.e., one lookup code will have multiple values one is current and rest are old values)
Scenario 1:
Employee table is having department_id : 10
Whereas department table is not having deparment_id : 10


Scenario 2:
In department table for department_id : 90 we are having two records but only one is active record
(we can understand based on effective date)

Output - Fact Table
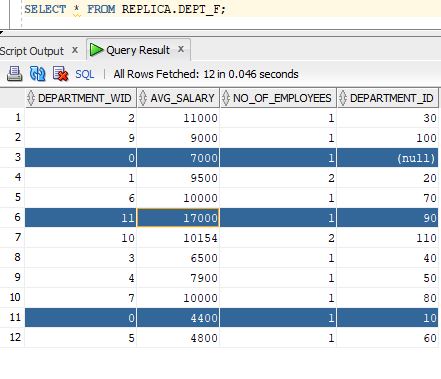
Whose department_id is not exists in department table for those department_wid is populated as 0
for rest those are populated from dimension table (row_wid column) as below

If you observe we are having multiple values for department_id : 90 but we picked only row_wid in the fact_table i.e., 11 (single value picked)
Approach:

In the lookup component, we can see match row rules
Multiple Match rows: (scenario 2) Select first single row (i.e., eff_dt desc - row_wid: 11)
Return a row with the following default values: (scenario 1) row_wid:0 (i.e., whenever there is no match then it will populate with 0)
Please comment out if you have any questions!!!!!!!!